May 2019
Summary
Parliamentary questions are a tool available to members of many legislatures, including the British House of Commons. They allow MPs to ask government ministers for information on the minister’s area of responsibility. MPs may use parliamentary questions for different purposes, such as to address local issues within their constituency, to bring focus on to broader policy issues or to encourage media attention on to a particular issue.
In this Data Byte we summarise assessment related questions asked of the Secretary of State for Education.
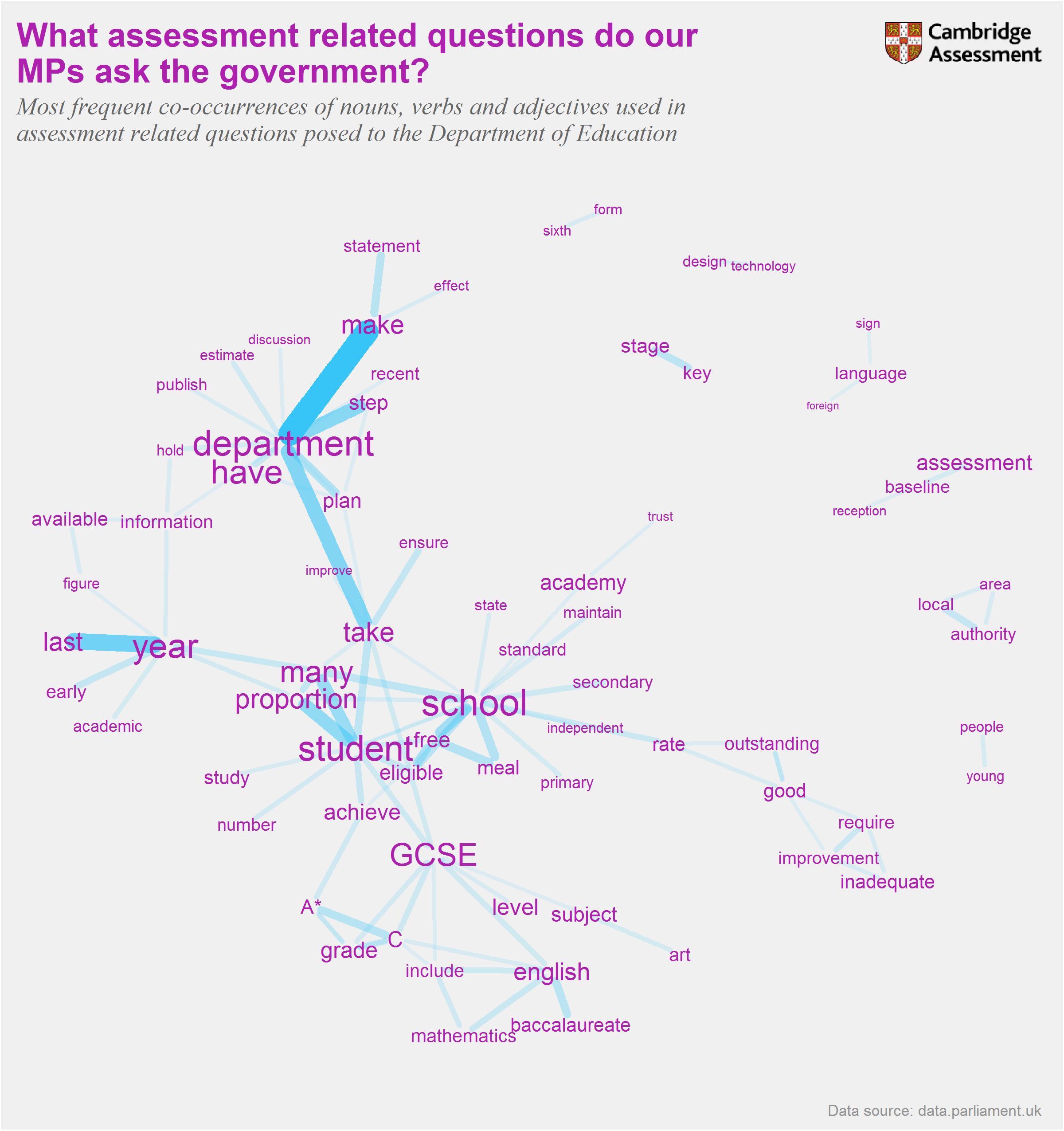
What does the chart show?
The word network summarises questions asked by MPs of the Secretary of State for Education over the last five years. The nodes are the words present in the 100 most frequently occurring pairs of nouns, verbs or adjectives that appear within three words of each other in a question. The nodes have been scaled according to the number of times they appear in the questions. The width and opacity of the link between two words is proportional to the number of times that those words co-occurred in a question.
Looking at the collocation of nouns, verbs and adjectives extracts the focus of the question. For example, in the question “To ask the Secretary of State for Education, how many students studied GCSE drama in each year since 2012?”, our analysis would extract “many-students”, “students-studied”, “many-studied”, “studied-GCSE”, “students-GCSE”, “studied-drama” and “GCSE-drama”. We used natural language processing tools to assign part-of-speech tags2 to each word in each question. This enabled us to determine the most frequently occurring collocations of selected parts-of-speech.3
We used an API provided by the UK Parliament to extract written and oral questions submitted to the Department of Education from 04-06-2014 to 08-04-2019. Parliamentary questions are classified under Hansard headings and we included questions that had assessment related words, such as “assessment”, “exam”, “standards”, and “qualifications”, in their Hansard heading. This resulted in 962 questions.
Why is the chart interesting?
The three most frequently occurring word pairs were “department-make”, “last-year” and “department-take”. This reveals one of the typical structures in the questions, asking how the government plans to respond to a particular issue. Many of the questions request data, as shown by the presence of “many” and “proportion” linked to “student”, as well as “available-information” and “available-figure”.
The word “school” is the most frequently occurring word, and appears in conjunction with “rate”, “good”, “outstanding” and “inadequate” indicating questions regarding Ofsted assessments. The words “eligible”, free" and “meal” are also clustered around “school” showing many questions related to those from disadvantaged backgrounds.
GCSE is the only qualification that appears in the network, this is unsurprising as GCSEs are taken by almost all children and so would be more likely to appear in the most frequently occurring words than higher level qualifications, such as A level, which are taken by fewer candidates.
Several subjects appear, and as could be expected these include English and Maths, however foreign languages, (British) Sign Language, Art and Design Technology are also present.
Further information
The text mining techniques used in this Data Byte enabled the summarisation and visual representation of the major themes present in a large amount of textual data. Previous Data Bytes have used other methods of text mining, such as topic analysis in Tweets on A level results day and sentiment analysis in Top GCSE news stories. Our research report, Changes in media coverage of GCSEs from 1988 to 2017, uses these techniques, and others, to examine how the British press has covered GCSEs over the past 30 years.
1. Each question begins with the same stem, “To ask the Secretary of State for Education”, and we have excluded this stem from our analysis.↩
2. Part-of-speech tags are annotations made to each word in a text to denote the category the word (or token) falls into, for example, noun, verb or adjective. These tags are based on both the definition of the word and it’s relationship to other words within the phrase or sentence that the word appears in.↩
3. To make the analysis clearer we took the lemma, or dictionary form, of each word. So, for example, “study”, “studied” and “studying” would be converted to “study”. We also combined the synonyms of some words. For example, “pupils”, “children” and “students” were amalgamated into “students”.↩